


Define your vision, audience, and goals to craft a clear roadmap.

Design user experiences and brand identities that resonate.

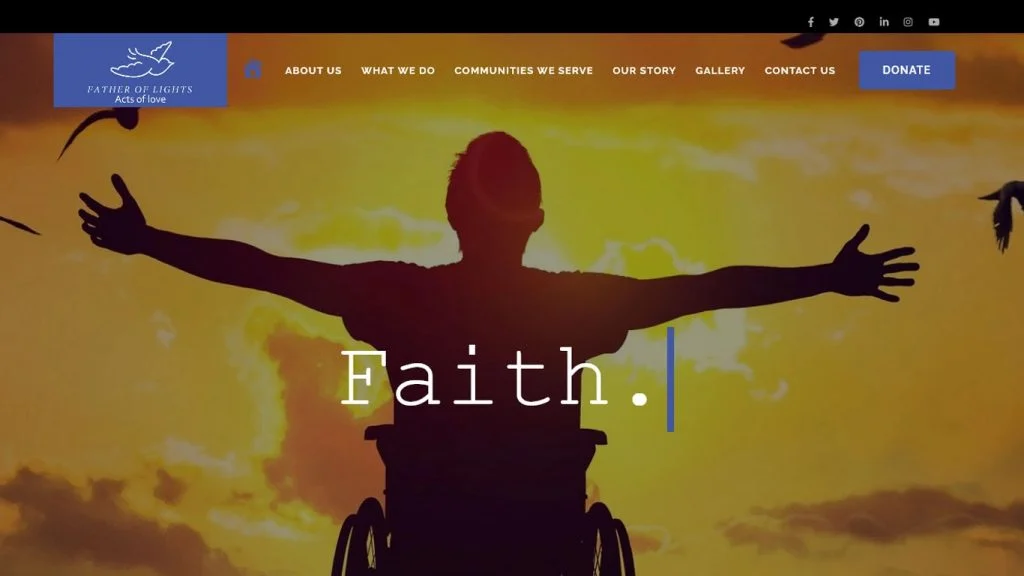
Develop websites, apps, software, and graphics that function flawlessly.

Launch your project and optimize it for success.

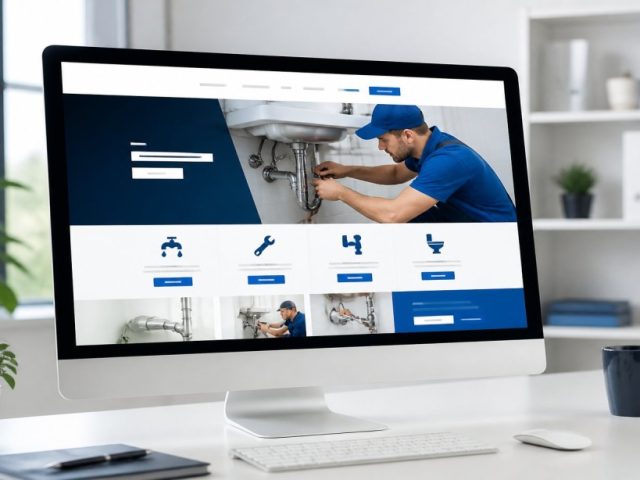
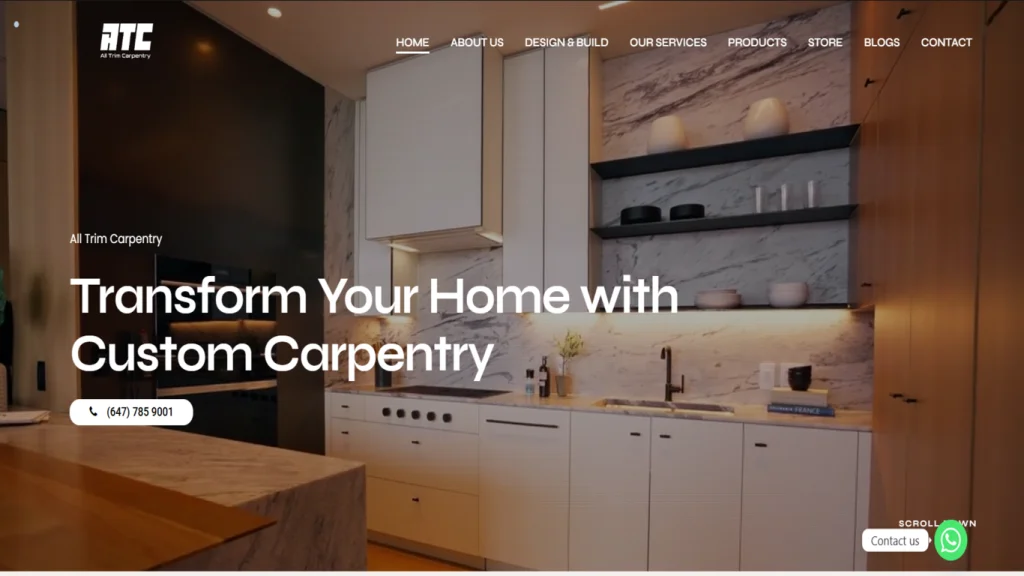
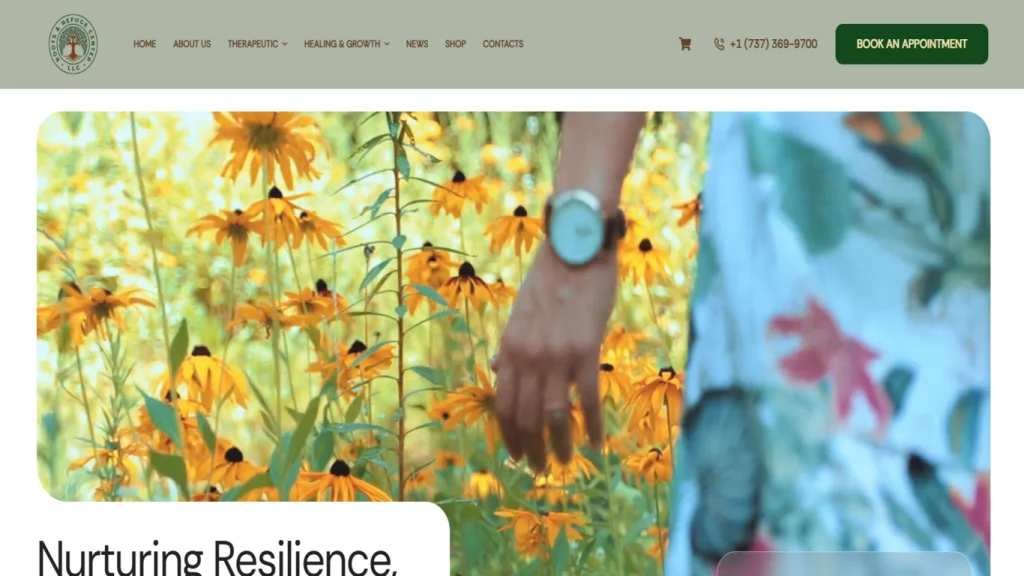
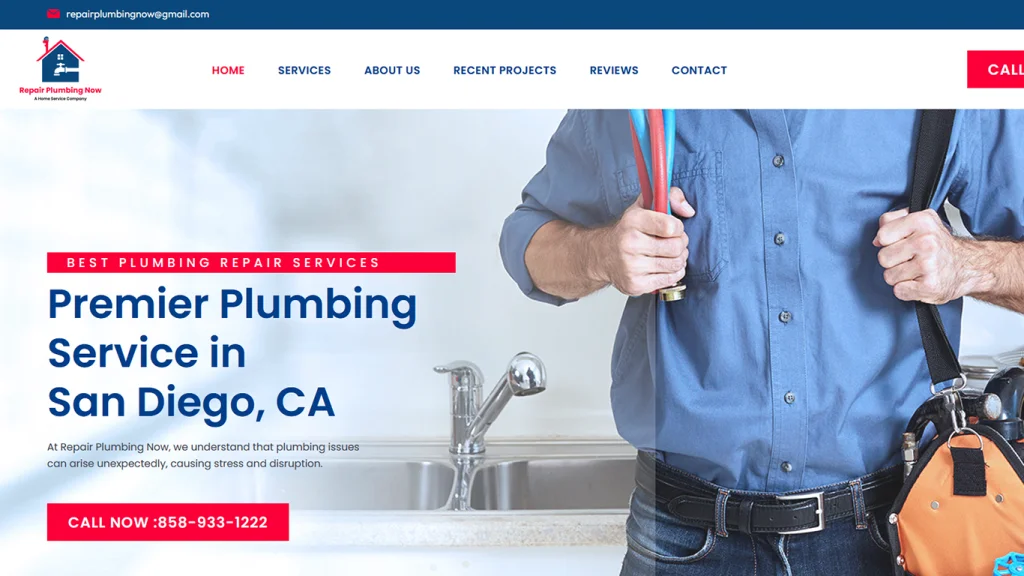
We create modern, responsive business websites optimized for speed, SEO/AEO/GEO, and conversions.

We build AI-powered mobile apps that deliver fast, seamless user experiences. Scalable, secure, and customized to your business goals

We improve rankings, visibility, and lead generation through SEO, AI search optimization, and high-performing ad campaigns.

We integrate AI systems using leading models like ChatGPT, Claude, Grok, Google AI, Perplexity, Copilot and Gemini to automate workflows and improve business efficiency.

We design clean, user-focused interfaces and graphics using Figma and Stitch to create seamless user experiences and strong visual branding.

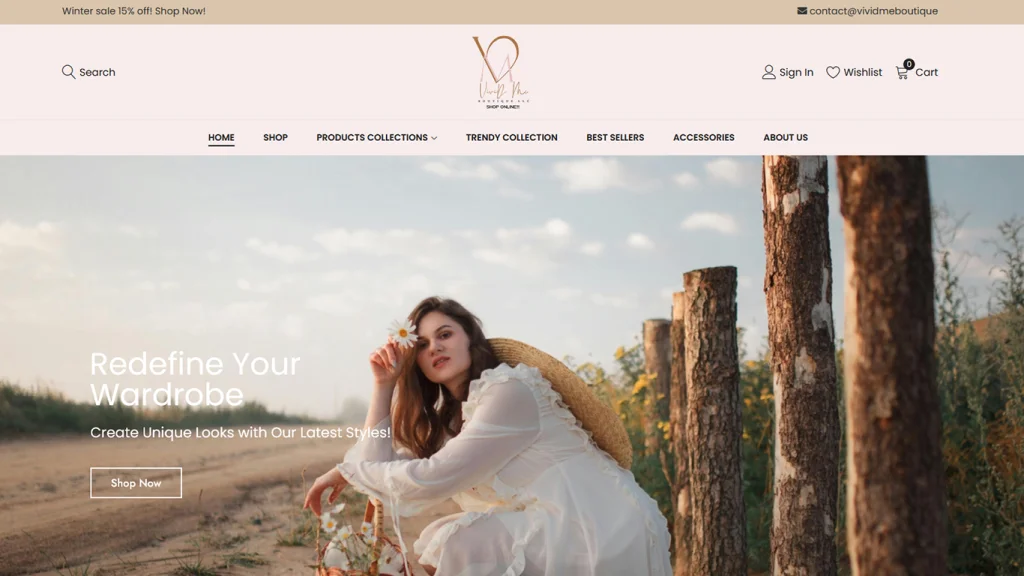
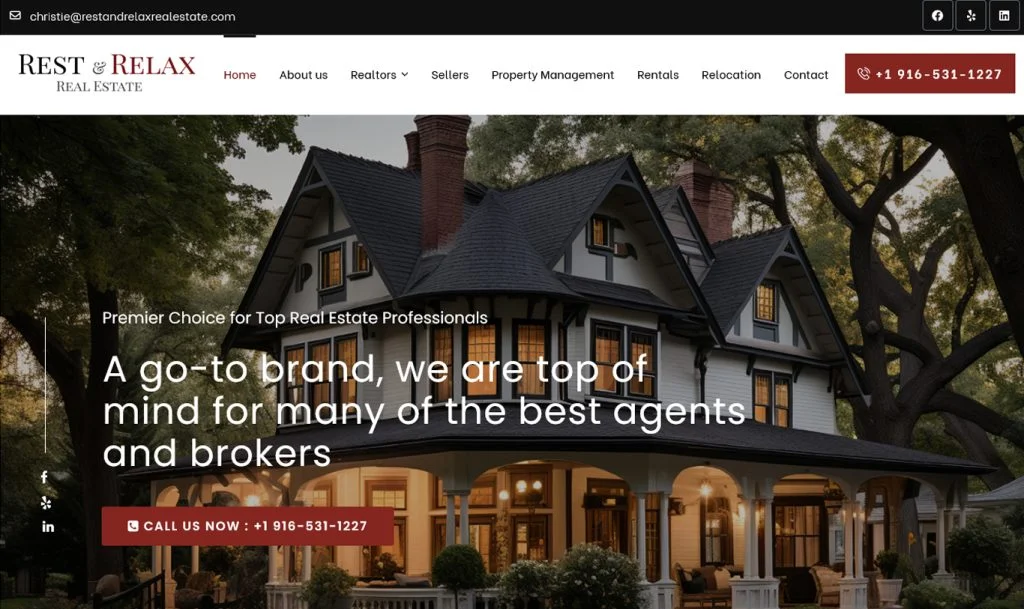
We optimize ecommerce stores to improve speed, increase conversions, and deliver seamless customer experiences.

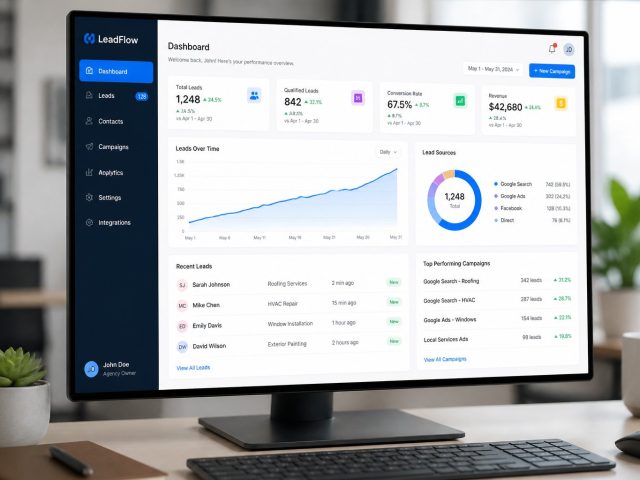
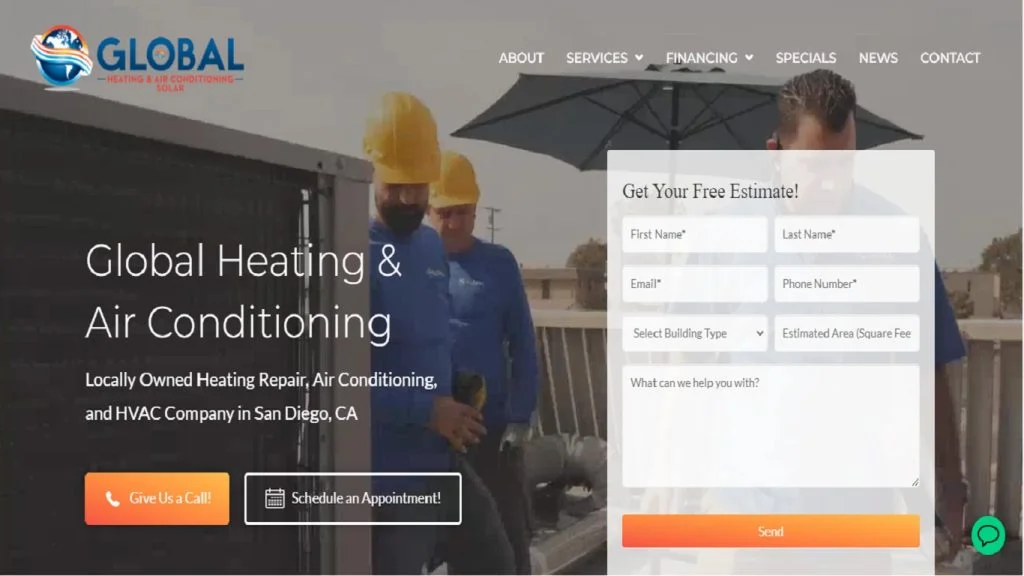
We build scalable ERP, CRM, AI-powered platforms, cloud systems, and enterprise software tailored to your business needs.

We collect, process, and analyze web data to deliver actionable insights and streamline business operations.































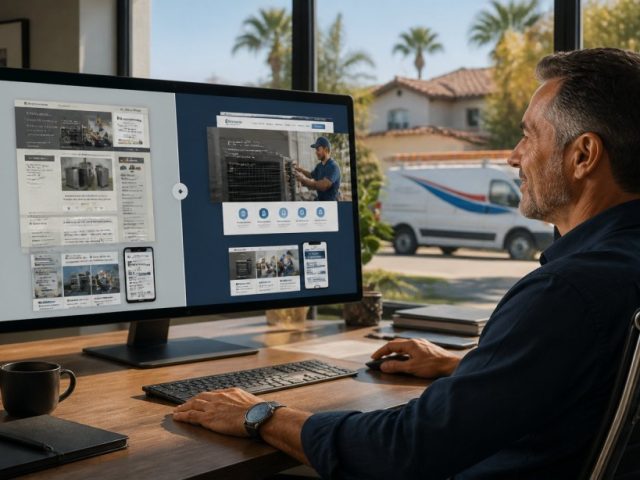



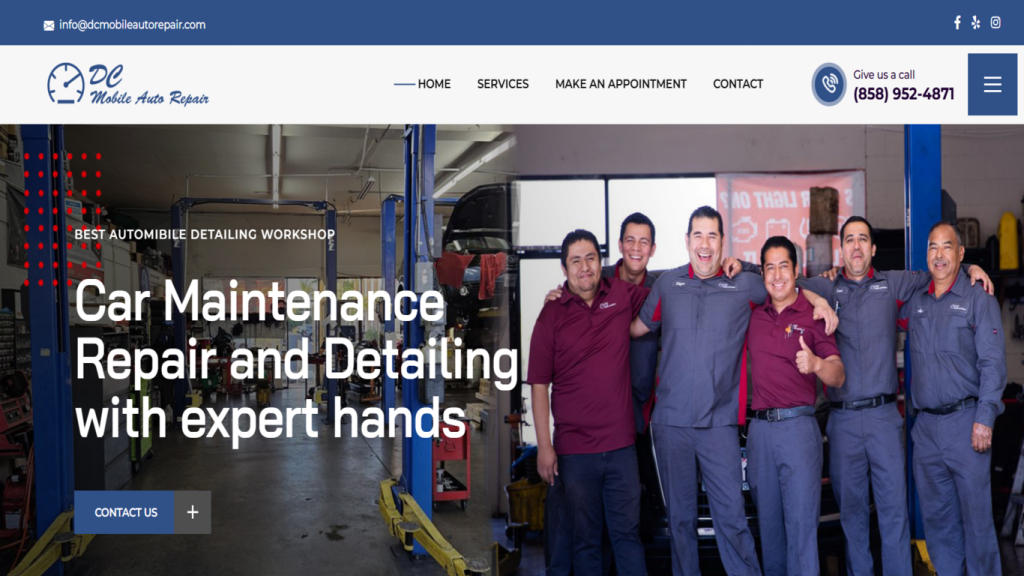




DC MOBILE AUTO REPAIR
1 year ago
I reached out to ZeOrbit to make changes to our website after the original developer I hired stopped responding to my calls. From the moment I contacted them, they were incredibly helpful. They assured me that the updates wouldn’t be an issue, and one of their team members would reach out to discuss the details further.
That same day, I received a call from Sam, who went over everything I needed and discussed pricing, which was very reasonable and fair. Although we encountered some bumps in the road due to issues from the original developer, Sam went above and beyond to ensure we got exactly what we needed. Not only did he complete the requested changes, but he also improved the layout, making the website look even more professional.
Throughout the process, Sam kept in constant communication, keeping us updated every step of the way. We’re incredibly happy to have found Sam and his team, and we will always turn to them for any future improvements to our website. Highly recommend!
That same day, I received a call from Sam, who went over everything I needed and discussed pricing, which was very reasonable and fair. Although we encountered some bumps in the road due to issues from the original developer, Sam went above and beyond to ensure we got exactly what we needed. Not only did he complete the requested changes, but he also improved the layout, making the website look even more professional.
Throughout the process, Sam kept in constant communication, keeping us updated every step of the way. We’re incredibly happy to have found Sam and his team, and we will always turn to them for any future improvements to our website. Highly recommend!

Brandon Vannier
1 year ago
I cant say enough how thankful I am to come across Sam and his team. He was able to take the ideas out of my head and put them onto an amazing website that has taken my business to the next level.
Stop thinking, and just trust the process! You won't be disappointed with ZeOrbit.
Stop thinking, and just trust the process! You won't be disappointed with ZeOrbit.

Jonabelle Hustoft
1 year ago
First and foremost, I would like to Thank Sam for making this process so smooth for me. I needed someone to build my business website, and I'm glad I went with this company. Sam was excellent to work with. He was flexible and knowledgeable and helped me build a beautiful website. He had my website finished in less than a week. He was also reasonable with his pricing. I appreciate his work ethic and I highly recommend Sam.

Campus Crossfire
1 year ago
Sam, the business owner, takes the time and makes the effort to understand the client so that his design is personalized and not just a cookie-cutter approach. He is creative in then designing the client's platform. And he is very reasonable in pricing and does not nickel and dime his clients.

Issa Watson
1 year ago
Holy s&$t I reach out to Sam after trying to build the site my self. I needed a new website for my contracting business and I was completely blown away. The speed, quality and professionalism from his team was top notch.
If you need anything from web design to SEO, they are the go to.
If you need anything from web design to SEO, they are the go to.

jamie simpson
2 years ago
I am so excited to work with Sam, their team did a phenomenal job on my website!!! The customer service was out of this world!! Everything was transparent and simplify for me to understand the process my website was undergoing. I would like to take the time out to thank them for being very understanding and explaining things to me, I would definitely recommend this company!!

Namir Ganni
2 years ago
From our initial consultation to the final launch, the ZeOrbit team demonstrated an unwavering commitment to understanding my unique business needs and translating them into cutting-edge digital solutions. Their attention to detail, responsiveness, and ability to meet tight deadlines were truly remarkable with respect to website designing and monthly result oriented SEO services.

Aristeo Felix
2 years ago
I recently had the pleasure of working with Best Website Designer, and I am thrilled with the results. From start to finish, the experience was seamless and highly professional. The standout aspects that make Best Website Designer deserving of a five-star review are their creative and modern designs, excellent communication, technical expertise, and timely delivery.

Gretchen Weidner
2 years ago
I received the most impeccable work on my website. I gave two references to model my website after and ZeOrbit seamlessly combined the two while also giving my site new branding for my business as well. They selected the right images, edited captions, created easy navigation and the best color formatting. They are also responsive and easy to get a hold of. I will continue to give ZeOrbit my business time and time again.

Marco Confuorto
2 years ago
I have used Zeorbit for complex business software applications, mobile applications, and websites. Zeorbit always delivers on their promises and does phenomenal work. Prices are competitive. Their turnaround time is crazy good. I highly recommend them. The guy that manages my account is Sam, he is phenomenal. Worth your time speaking with him.